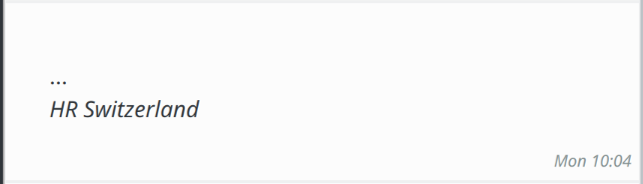
- You can now view “flagged”/”starred” messages per account. This is a short-cut to getting that functionality eventually folded into the todo view (I think…), and allows you to quickly show a list of messages that you have marked as important so you can deal with them. The view works best if there is a small number of marked messages, and you unflag them once you have dealt with them.
- The experimental flatpak now contains spellcheck-highlighting support based on sonata. There is no configuration (language is autodetected per sentence), and there is also no UI to get to corrections, so it’s primarily useful to spot typos (which is good enough for the time being).
- Quotes in plaintext emails are now highlighted, which makes for a better reading experiece.
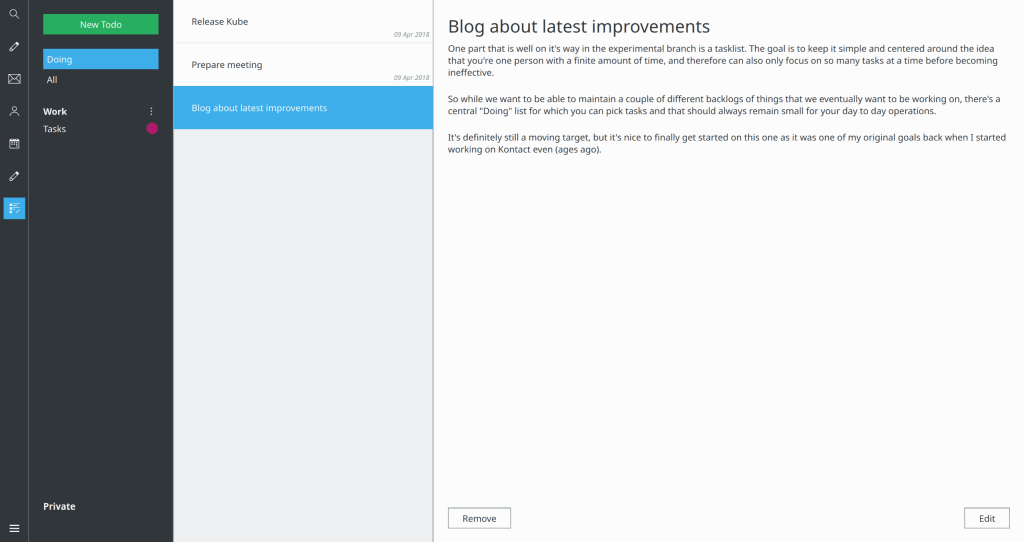
- Lot’s of enhancements to the todo view, which is now very functional as a day-to-day todo manager.
- The todo-view now has an Inbox that shows all tasks that are neither done, nor in doing. This allows to go through open tasks from all task-lists, to pick them for the “Doing” list (which represents the set you’re currently working on).
- Various fixes to the invtation-management code to work correctly with exceptions to recurrences.
- Kube is now a single-instance application when run with the –lockfile option (as used in the flatpak). This was necessary to to deal with the fact that we can’t start multiple instances of kube in separate sandboxes, because storage and lockfiles rely on PID uniqueness. Starting kube again will now simply hide and show the window of the current instance, which results in the window showing up on the workspace you currently are (which also seems to be more consitent with how Gnome and MacOS behave.
- The IMAP synchronization got more efficient, primarily enhancing the case where nothing changed on folders.
- Adapted to source changes in KCalendarCore (so the Applications/19.08 release is now required)
- It’s now possible to create/remove calendars and tasklists in Kube, and sink can modify the associated color (but there’s no UI yet).
- Recipients in the email composer can now be moved between To/CC/BCC using drag and drop.
- Listviews now have subtle fade-in animations, which helps spotting new items.
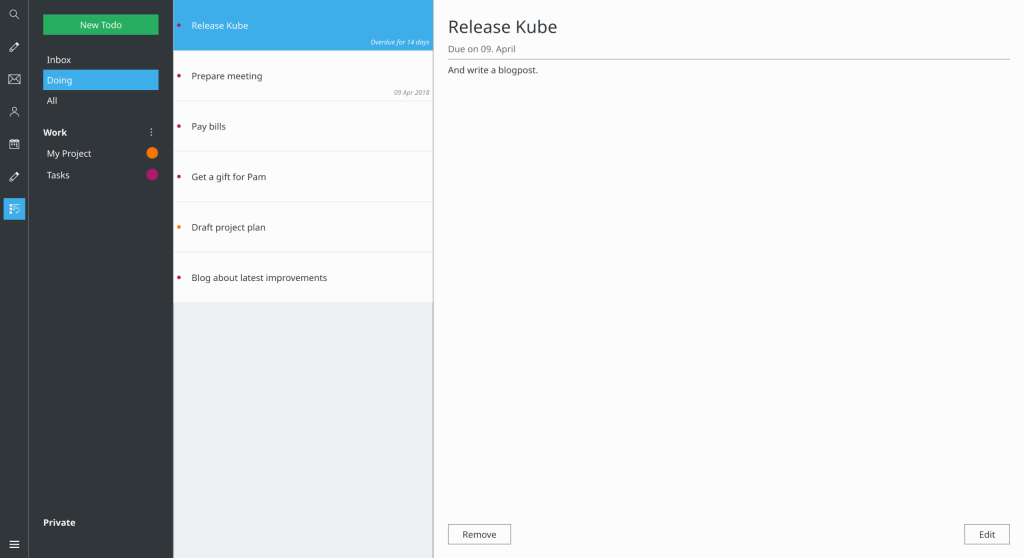
Todoview with an Inbox 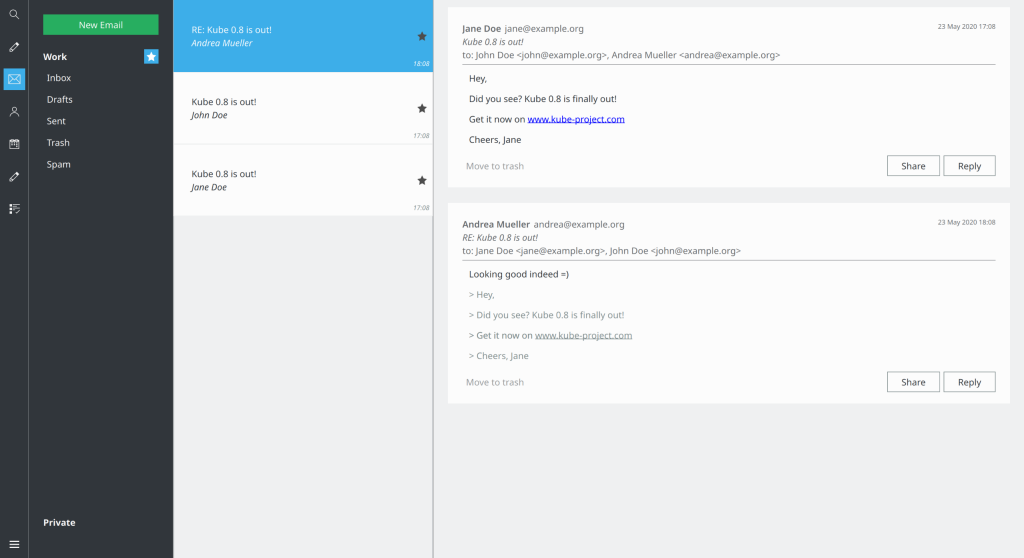
The new “starred” view 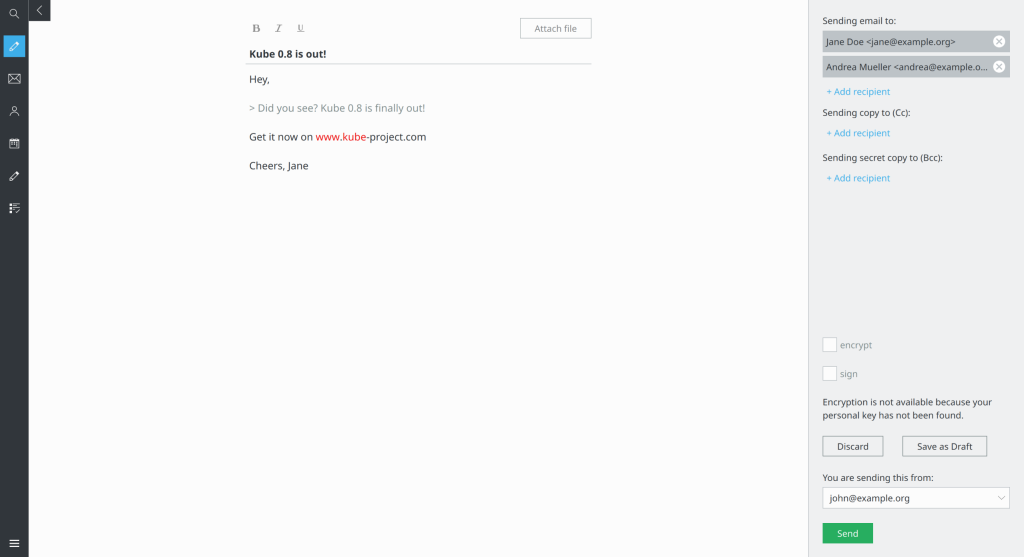
Quotes and spellchecking
More information on the Kolab Now blog!
“Kube is a modern communication and collaboration client built with QtQuick on top of a high performance, low resource usage core. It provides online and offline access to all your mail, contacts, calendars, notes, todo’s and more. With a strong focus on usability, the team works with designers and UX experts from the ground up, to build a product that is not only visually appealing but also a joy to use.” For more info, head over to: kube-project.com